턴제 번역의 종말: Gemini 3.5 Live Translate API와 LiveKit으로 구현하는 실시간 동시통역

글로벌 서비스를 개발할 때 항상 마주치는 가장 거대한 벽은 '언어'입니다. 지금까지의 AI 번역은 대부분 연사의 말이 완전히 끝날 때까지 기다렸다가 텍스트를 추출하고 번역하는 '턴제(Turn-by-turn)' 방식이 주를 이뤄왔습니다. 아무리 성능이 좋아도 대화의 흐름이 뚝뚝 끊기는 어색함은 지우기 어려웠죠.
최근 구글이 발표한 음성 대 음성(Speech-to-Speech) 모델인 Gemini 3.5 Live Translate는 이 패러다임을 완전히 바꿨습니다. 말이 끝나기를 기다리지 않고, 오디오 스트리밍 데이터를 실시간으로 처리해 연사의 어조(Pitch)와 페이스(Pacing)를 유지하며 단 몇 초 뒤를 자연스럽게 따라붙는 동시통역을 선보인 것입니다.
이번 글에서는 구글의 공식 아키텍처와 기술 스펙을 살펴보고, 오픈소스 라이브 미디어 프레임워크인 LiveKit 예제를 기반으로 직접 진행한 글로벌 컨퍼런스(Google I/O 및 Xiaomi 컨퍼런스) 교차 언어 테스트 결과를 공유합니다.
1. 기술적 아키텍처와 주요 스펙 고찰
구글 개발자 블로그와 오피셜 데모에서 공개된 Gemini 3.5 Live Translate의 핵심은 '컨텍스트 가중치와 레이턴시의 실시간 밸런싱'입니다.
- 연속형 스트리밍 번역 (Continuous Generation): 문장이 끝날 때까지 대기하지 않습니다. 실시간으로 들어오는 오디오 청크(Chunk)를 분석하면서, 전체 맥락을 파악하기 위해 '잠시 기다리는 시간'과 동시성을 유지하기 위해 '즉시 번역하는 시간' 사이의 트레이드오프(Trade-off)를 모델 스스로 완벽하게 조율합니다.
- Zero-Configuration 다국어 자동 감지: 인풋 언어를 고정할 필요가 없습니다. 70개 이상의 언어를 자동으로 인식하며, 대화 도중 언어가 스위칭되어도 별도의 API 파라미터 수정 없이 스트리밍을 그대로 유지합니다.
- 미디어 인프라와의 결합: 실시간 오디오 스트리밍 인터페이스를 프로덕션 레벨로 빌드하는 것은 개발자에게 꽤나 고통스러운 작업입니다. 구글은 이를 해결하기 위해 LiveKit, Agora, Fishjam 등 대표적인 RTC(Real-Time Communication) 플랫폼들과 손을 잡았습니다. 특히 구글이 예제로 공개한
gemini-live-translate-livekit저장소는 LiveKit Agents 환경에서 다국어 유저가 각자의 언어로 방에 참여해 실시간 음성을 주고받을 수 있는 파이프라인을 직관적으로 보여줍니다.
2. 스트리밍 실전 검증: Google I/O & Xiaomi 컨퍼런스 데드라인 테스트
구글이 제시한 이상적인 데모 환경을 넘어, 노이즈가 많고 전문 기술 용어가 난무하는 실제 글로벌 테크 컨퍼런스 환경에서 이 모델이 얼마나 버텨줄지 궁금했습니다.
이를 검증하기 위해 오픈소스 깃허브 예제를 기반으로 테스트 환경을 구축하고, Google I/O 키노트와 샤오미(Xiaomi) 신제품 발표회 라이브 스트리밍을 오디오 소스로 밀어 넣었습니다. 특히, AI를 괴롭히기 위해 발표 중간에 강제로 언어를 스위칭하는 '교차 언어(Code-switching) 환경'을 연출했습니다.
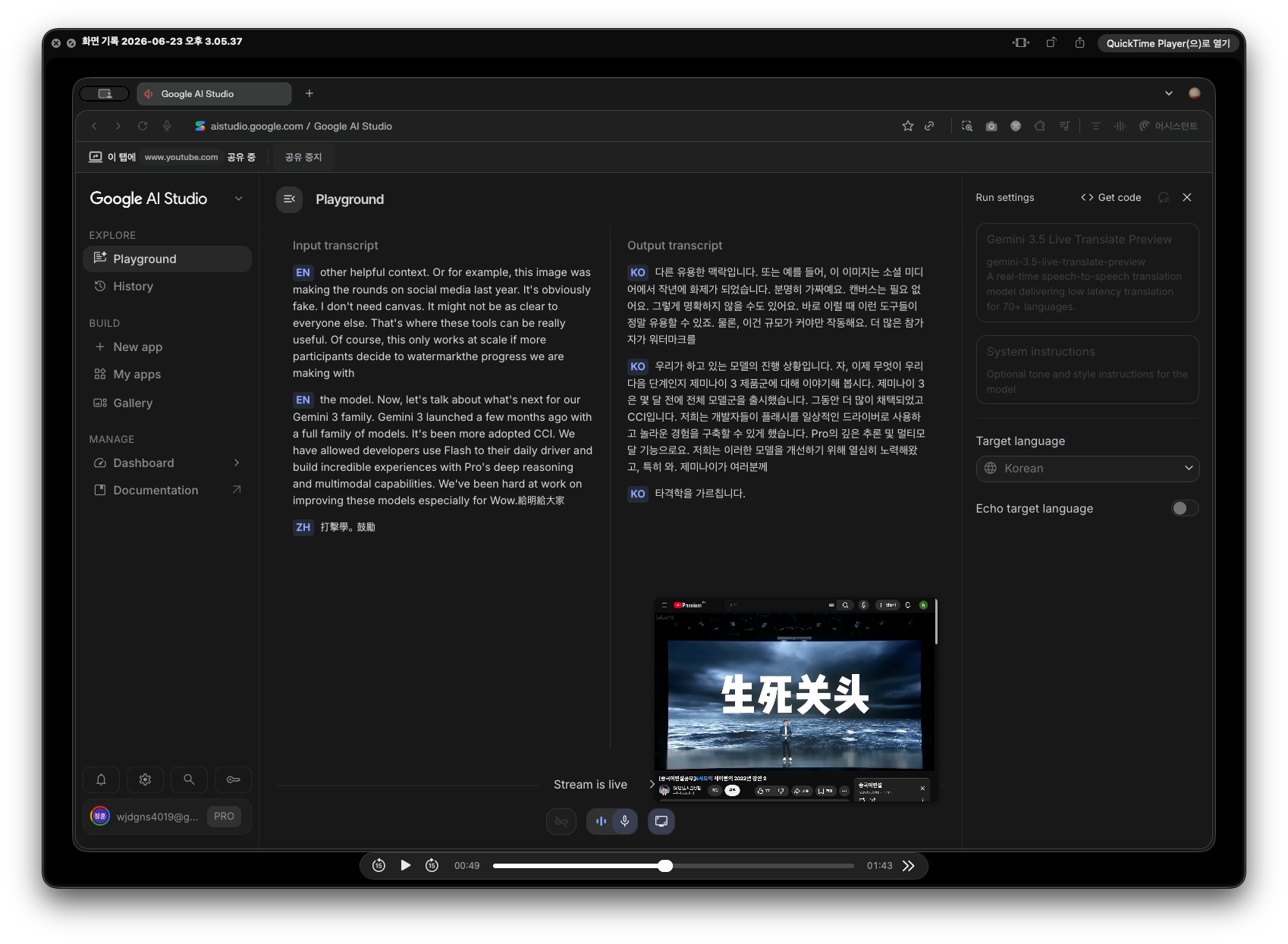
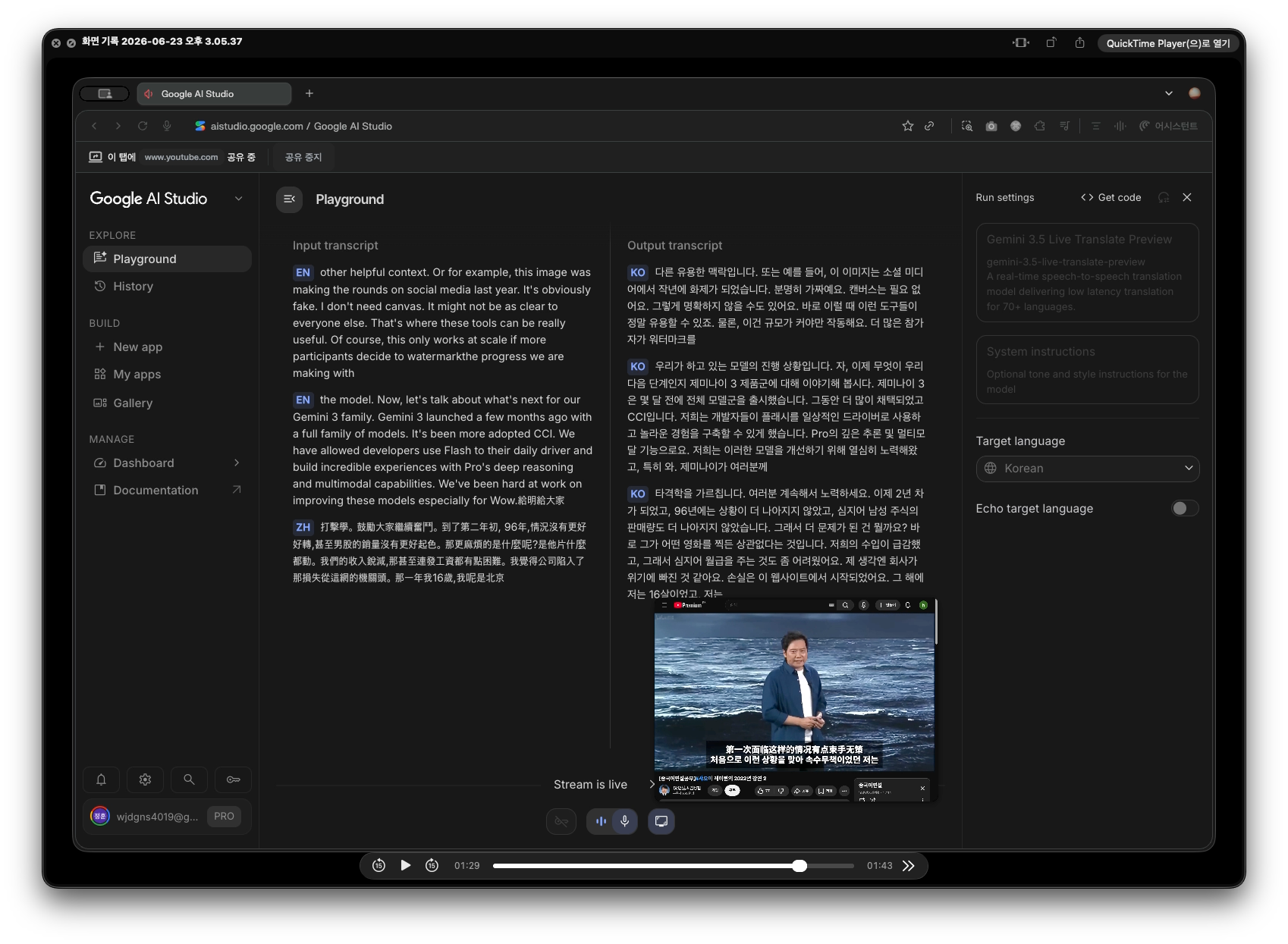
💡 주요 테스트 인사이트
- 테스트 1: Google I/O 키노트 (영어/힌디어 교차 인풋)
구글 오피셜 데모에서도 다뤄진 조합이지만, 실제 무대 마이크 특유의 공간 잔향(Reverb)이 있는 상태에서도 레이턴시는 2~3초 수준을 유지했습니다. 연사가 기술적인 배경 설명을 하다가 감탄사나 뉘앙스를 바꿀 때, 번역된 음성의 억양과 데시벨이 자연스럽게 연동되는 부분에서 SOTA(최고 수준) 모델의 디테일을 느낄 수 있었습니다.
- 테스트 2: Xiaomi 컨퍼런스 (중국어/영어 다중 스위칭 인풋)
중국어로 신제품 스펙을 다다다 설명하다가 중요한 칩셋 명칭이나 벤치마크 점수를 영어 용어로 뱉는 상황, 그리고 아예 중간에 발표 언어를 전환하는 극한의 환경을 시뮬레이션했습니다. 보통의 STT+MT 구조에서는 언어 셋이 꼬이면서 텍스트가 깨지기 십상인데, Gemini 3.5는 오디오 흐름을 놓치지 않고 중국어 톤에서 영어 테크니컬 키워드로 넘어가는 구간을 매끄럽게 소화했습니다. 몇 단어 지나지 않아 타깃 언어 세팅이 자동으로 정렬되는 반응 속도가 압권이었습니다.
3. 프로덕션 도입 관점에서의 비즈니스 가치
현재 구글은 차량 공유 플랫폼 Grab(그랩)을 통해 드라이버와 외국인 여행자 간의 실시간 통화에 이 모델을 실전 테스트 중이며, CJ ENM과도 글로벌 콘텐츠 시청 경험을 위한 협업을 진행하고 있다고 밝혔습니다.
개발자 입장에서 주목해야 할 점은, 이 모델이 단순 실험실 수준이 아니라 Google Meet(최대 2,000개 이상의 언어 조합 지원)이나 구글 번역 앱의 '리스닝 모드(전화 통화하듯 귀에 대고 실시간 통역을 듣는 기능)'처럼 이미 프로덕션 서비스에 직접 이식되고 있다는 사실입니다. 모든 오디오 출력물에 구글의 미세 워터마크 기술인 SynthID가 내장되어 안전성(Misinformation 방지) 측면까지 챙긴 점도 엔터프라이즈 환경에서 도입을 고려할 때 가산점이 될 만한 요소입니다.
4. 글을 마치며
Gemini 3.5 Live Translate API와 LiveKit의 조합은 전 세계의 청중이 각자의 언어로 실시간 세션에 참여하는 웨비나 플랫폼, 글로벌 고객을 응대하는 컨택 센터, 혹은 다국어 유저가 협업하는 SaaS 툴을 만들 때 치트키가 될 수 있습니다. 미디어 스트리밍 파이프라인만 잘 잡아둔다면 AI 연동 자체는 크게 까다롭지 않은 수준까지 도달했습니다.
이번에 테스트를 진행한 구글의 공식 오픈소스 샘플 코드가 궁금하신 분들은 아래 레포지토리를 참고해 보세요.
참고 링크