Integrating ReID into a Kotlin Real-Time YOLO detector
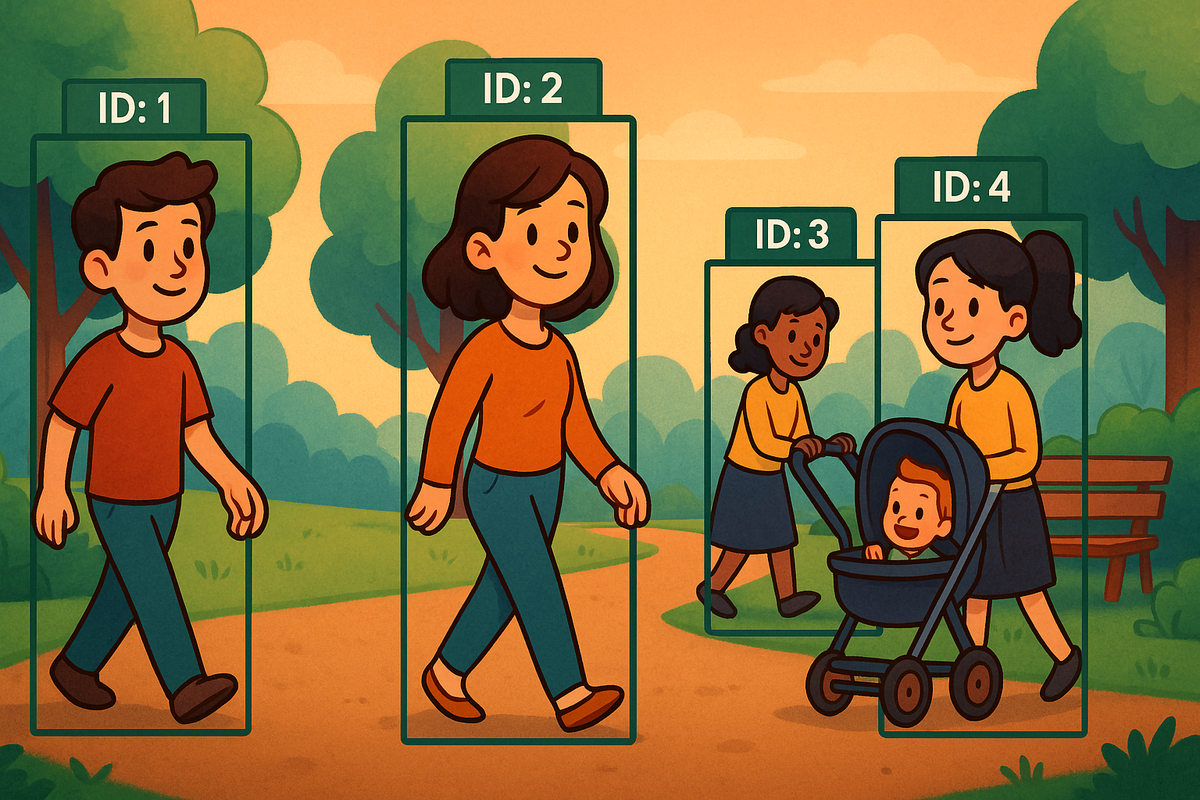
This task still fascinates me each time we revisit it, there’s room to push efficiency further. In earlier posts, such as our most-read entry Real-Time Human Detection and ReID with YOLO + OSNet, we walked step by step from raw image frames to bounding boxes with unique IDs for each detected individual. That workflow worked, but its structure left room for improvement.
In this post, we take the same idea and reimagine it with a more streamlined pipeline bridging Flutter → Kotlin → C++ and back while keeping visualization in focus.
Make sure to subscribe! it is free to do so and you can get access to our python notebooks and Github Repos/Gist's for future post so you can recreate it for your use-cases. Also you can contact us directly once subscribed.
Handling YUV on Android: From Camera and Decoder to RGB Floats
A crucial part of the pipeline is how we extract frames. The naive approach, grabbing a Bitmap for each frame and converting it into an RGB buffer is simple but extremely resource-intensive and should be avoided. Instead, we want to pull frames directly from the camera feed or video decoder so processing can begin immediately. The trade-off is that this requires careful orchestration to convert from YUV to RGB, and the main challenge is understanding the exact YUV variant each Android device provides. Most frames arrive in some form of YUV 4:2:0, which is efficient but messy: planes may be planar or semi-planar, strides are often padded, and in some cases vendors even swap U and V channels. Our models, however, don’t care about those quirks. They just need a consistent planar I420 layout and, ultimately, normalized float RGB. The task, then, is to standardize the entire path from raw YUV frames to stable RGB tensors for inference.
When MediaCodec changes output format, we record the color format and the effective strides. This tells us whether to expect planar vs semi-planar chroma and how wide each row really is in memory. If the codec doesn’t provide strides yet, we fall back to sensible defaults.
class YuvConverter(private val tag: String) {
private var colorFormat = MediaCodecInfo.CodecCapabilities.COLOR_FormatYUV420Planar
private var actualYStride = 0
private var actualUVStride = 0
private var actualUVPixelStride = 1
fun handleFormatChange(outputFormat: MediaFormat) {
if (outputFormat.containsKey(MediaFormat.KEY_COLOR_FORMAT)) {
colorFormat = outputFormat.getInteger(MediaFormat.KEY_COLOR_FORMAT)
Log.d(tag, "Decoder output color format: $colorFormat")
}
actualYStride = if (outputFormat.containsKey("stride"))
outputFormat.getInteger("stride") else outputFormat.getInteger(MediaFormat.KEY_WIDTH)
actualUVStride = when (colorFormat) {
MediaCodecInfo.CodecCapabilities.COLOR_FormatYUV420Planar -> actualYStride / 2
MediaCodecInfo.CodecCapabilities.COLOR_FormatYUV420SemiPlanar -> actualYStride
else -> actualYStride / 2
}
actualUVPixelStride = when (colorFormat) {
MediaCodecInfo.CodecCapabilities.COLOR_FormatYUV420SemiPlanar -> 2
else -> 1
}
Log.d(tag, "Format - Y stride: $actualYStride, UV stride: $actualUVStride, UV pixel stride: $actualUVPixelStride")
}With format known, we create per-frame metadata and reusable scratch buffers. This also clamps default strides if the codec hasn’t emitted them yet.
private var frameMetadata: FrameMetadata? = null
private var reusable: ReusableBuffers? = null
fun initializeFrameMetadata(srcWidth: Int, srcHeight: Int) {
if (frameMetadata?.srcWidth == srcWidth && frameMetadata?.srcHeight == srcHeight) return
val chromaW = srcWidth / 2
val chromaH = srcHeight / 2
val yStride = if (actualYStride > 0) actualYStride else srcWidth
val uvStride = if (actualUVStride > 0) actualUVStride else (srcWidth / 2)
if (actualYStride == 0) actualYStride = srcWidth
if (actualUVStride == 0) actualUVStride = uvStride
if (actualUVPixelStride == 0) actualUVPixelStride = 1
frameMetadata = FrameMetadata(
srcWidth, srcHeight, chromaW, chromaH,
yPlaneSize = yStride * srcHeight,
uvPlaneSize = uvStride * chromaH,
interleavedUVSize = uvStride * chromaH
)
val maxUVSize = chromaW * chromaH
reusable = ReusableBuffers(
uBuffer = ByteBuffer.allocateDirect(maxUVSize).order(ByteOrder.nativeOrder()),
vBuffer = ByteBuffer.allocateDirect(maxUVSize).order(ByteOrder.nativeOrder()),
contiguousY = ByteBuffer.allocateDirect(srcWidth * srcHeight).order(ByteOrder.nativeOrder())
)
Log.d(tag, "Initialized frame metadata: ${srcWidth}x${srcHeight}, format: $colorFormat")
}This gives us enough information for us to know what to do next. How to interpret the incoming frames in order to turn them into an RGB configuration.
From YUV to Canonical I420
For each decoded frame, we decide what (if anything) must change to yield tight planar I420 (Y, then U, then V; pixelStride=1). If the buffer is already I420-compatible, no chroma rework is needed. The flow is:
- Extract a contiguous Y plane (respecting row stride).
- Branch by chroma layout: planar vs semi-planar.
- If semi-planar, de-interleave UV into tight planar U and V.
- Because some vendors output NV21-like ordering, run a one-time U/V auto-swap probe.
@Volatile private var chromaSwap: Boolean = false
fun setChromaSwap(enable: Boolean) { chromaSwap = enable }
private var autoSwapDecided = false
private var autoSwap = false
fun convertYuvToRgb(
srcBuffer: ByteBuffer, size: Int,
srcWidth: Int, srcHeight: Int,
rgbOut: ByteBuffer,
targetWidth: Int = 384, targetHeight: Int = 384
) {
val meta = frameMetadata!!
val reused = reusable!!
// Y: contiguous (de-strided if needed)
val (yPlane, yBytes) = extractYPlane(srcBuffer, size, srcWidth, srcHeight, reused)
val remaining = size - yBytes
// UV: planar vs semi-planar
var usedSemiPlanar = false
var (uPlane, vPlane) = when (colorFormat) {
MediaCodecInfo.CodecCapabilities.COLOR_FormatYUV420Planar ->
extractPlanarUV(srcBuffer, yBytes, remaining, srcHeight)
MediaCodecInfo.CodecCapabilities.COLOR_FormatYUV420SemiPlanar -> {
usedSemiPlanar = true
extractSemiPlanarUV(srcBuffer, yBytes, remaining, meta, reused)
}
else -> if (remaining >= (actualUVStride * (srcHeight / 2))) {
usedSemiPlanar = true
extractSemiPlanarUV(srcBuffer, yBytes, remaining, meta, reused)
} else {
extractPlanarUV(srcBuffer, yBytes, remaining, srcHeight)
}
}
// One-time U/V order probe for semi-planar sources
if (usedSemiPlanar && !autoSwapDecided) {
val uvStridePlanar = meta.chromaW
val uvPixStridePlanar = 1
autoSwap = detectChromaSwap(yPlane, uPlane, vPlane, srcWidth, srcHeight, uvStridePlanar, uvPixStridePlanar)
autoSwapDecided = true
Log.d(tag, "Auto-detected chroma swap: $autoSwap")
}
val doSwap = if (usedSemiPlanar) autoSwap || chromaSwap else chromaSwap
if (doSwap) { val tmp = uPlane; uPlane = vPlane; vPlane = tmp }
// Semi-planar was de-interleaved → tight planar; tell native the planar strides
val uvStrideForCall = if (usedSemiPlanar) meta.chromaW else actualUVStride
val uvPixelStrideForCall = if (usedSemiPlanar) 1 else actualUVPixelStrideAt this point we hold a clean, tight I420 (contiguous Y, planar U and V, correct U/V order). This is the ideal input for our native pre-processing (resize + scale + rotate + I420→RGB + float normalization).
From I420 to RGB
To turn I420 to the RGB specification our model is expecting as input we relied on the native library libyub to efficiently perform all the actions we need for our pipeline. Have a look at the code below which is the starting point for the transformations:
JNIEXPORT void JNICALL
Java_life_aicu_gait_NativeBridge_resizeI420(
JNIEnv* env, jclass /* clazz */,
jobject yBuf, jint yRowStride,
jobject uBuf, jint uRowStride, jint uPixelStride,
jobject vBuf, jint vRowStride, jint vPixelStride,
jint srcW, jint srcH,
jobject dstFBuf, jint dstW, jint dstH, jint rotationDegrees) {
// 1) Get raw plane pointers
const uint8_t* srcY = reinterpret_cast<const uint8_t*>(env->GetDirectBufferAddress(yBuf));
const uint8_t* srcU = reinterpret_cast<const uint8_t*>(env->GetDirectBufferAddress(uBuf));
const uint8_t* srcV = reinterpret_cast<const uint8_t*>(env->GetDirectBufferAddress(vBuf));
float* dstF = reinterpret_cast<float*>(env->GetDirectBufferAddress(dstFBuf));Notice that we actually don't pass the image directly, no Kotlin specific instance crosses JNI. Kotlin hands native code raw pointers to the Image planes via direct ByteBuffers, so the YUV read is zero‑copy across the boundary. The JNI call is synchronous; native does its work, writes directly into a preallocated float buffer, and returns. No pointers are retained, so the producer can safely reuse/release the Image memory immediately after the call.
What this buys:
- Zero‑copy JNI handoff: only pointers + stride metadata are passed.
- Minimal repacking: only when pixelStride==2 (NV12/NV21) or when scaling/rotating; otherwise libyuv consumes planar I420 with row strides.
- Single preallocated destination: a direct float NHWC buffer reused per frame.
Scaling
// 2) Determine if scaling required (fast path when destination matches source)
bool noScale = (dstW == srcW && dstH == srcH);
int scaledW = dstW;
int scaledH = dstH;
int scaledChW = (scaledW + 1) >> 1;
int scaledChH = (scaledH + 1) >> 1;
if (!noScale) {
// Allocate / resize scale buffers only if dimensions changed
if (scaledW != lastScaledW || scaledH != lastScaledH) {
yScaled.resize(size_t(scaledW) * scaledH);
uScaled.resize(size_t(scaledChW) * scaledChH);
vScaled.resize(size_t(scaledChW) * scaledChH);
lastScaledW = scaledW;
lastScaledH = scaledH;
}
// Perform scaling
libyuv::I420Scale(
srcY, yRowStride,
srcU, uRowStride,
srcV, vRowStride,
srcW, srcH,
yScaled.data(), scaledW,
uScaled.data(), scaledChW,
vScaled.data(), scaledChW,
scaledW, scaledH,
libyuv::kFilterBilinear
);
}Rotation
// 3) Optionally rotate
int rot = rotationDegrees % 360;
int finalW = scaledW;
int finalH = scaledH;
int finalChW = scaledChW;
const uint8_t* yPtr;
const uint8_t* uPtr;
const uint8_t* vPtr;
LOGI("Resize I420: src %dx%d, dst %dx%d, rotation %d, mode=%s",
srcW, srcH, dstW, dstH, rot, noScale ? "passthrough" : "scale");
if (rot != 0) {
// Compute final dims for rotation
finalW = (rot % 180 == 0) ? scaledW : scaledH;
finalH = (rot % 180 == 0) ? scaledH : scaledW;
finalChW = (finalW + 1) >> 1;
int finalChH = (finalH + 1) >> 1;
// Allocate rotation buffers only when size changes
if (finalW != lastFinalW || finalH != lastFinalH) {
yRot.resize(size_t(finalW) * finalH);
uRot.resize(size_t(finalChW) * finalChH);
vRot.resize(size_t(finalChW) * finalChH);
rgbBuffer.resize(size_t(finalW) * finalH * 3);
lastFinalW = finalW;
lastFinalH = finalH;
}
// Map degrees → RotationMode
libyuv::RotationMode mode;
switch (rot) {
case 90: mode = libyuv::kRotate90; break;
case 180: mode = libyuv::kRotate180; break;
case 270: mode = libyuv::kRotate270; break;
default: mode = libyuv::kRotate0; break;
}
if (noScale) {
// Rotate directly from original planes
libyuv::I420Rotate(
srcY, yRowStride,
srcU, uRowStride,
srcV, vRowStride,
yRot.data(), finalW,
uRot.data(), finalChW,
vRot.data(), finalChW,
srcW, srcH,
mode
);
} else {
libyuv::I420Rotate(
yScaled.data(), scaledW,
uScaled.data(), scaledChW,
vScaled.data(), scaledChW,
yRot.data(), finalW,
uRot.data(), finalChW,
vRot.data(), finalChW,
scaledW, scaledH,
mode
);
}
yPtr = yRot.data();
uPtr = uRot.data();
vPtr = vRot.data();
} else {
// No rotation path
finalW = scaledW; finalH = scaledH;
if (finalW != lastFinalW || finalH != lastFinalH) {
rgbBuffer.resize(size_t(finalW) * finalH * 3);
lastFinalW = finalW; lastFinalH = finalH;
}
if (noScale) {
yPtr = srcY; uPtr = srcU; vPtr = srcV; // direct passthrough
} else {
yPtr = yScaled.data(); uPtr = uScaled.data(); vPtr = vScaled.data();
}
}RGB Transformation and Normalization
// 4) Convert I420 → RGB24 (packed)
libyuv::I420ToRGB24(
yPtr, finalW,
uPtr, finalChW,
vPtr, finalChW,
rgbBuffer.data(), finalW * 3,
finalW, finalH
);
// 5) Normalize to float [0,1]
const float inv255 = 1.0f / 255.0f;
size_t pixelCount = size_t(finalW) * finalH;
uint8_t* rawRgb = rgbBuffer.data();
for (size_t i = 0, j = 0; i < pixelCount; ++i, j += 3) {
dstF[j + 0] = rawRgb[j + 0] * inv255;
dstF[j + 1] = rawRgb[j + 1] * inv255;
dstF[j + 2] = rawRgb[j + 2] * inv255;
}That's it for preprocessing at this point we have a nicely formatted flat buffer representation of the image we need to input in our model in the shape that traditionally all yolo models are configured for [BCHW].
Passing RGB to YOLO and staging results for NMS
Once we’ve standardized our frames into RGB tensors, the next step is to push them into YOLO for inference. The important detail here is how we stage the results so that post-processing (like Non-Max Suppression, or NMS) doesn’t block the main inference loop.
Running Inference
Our inference engine reads directly from the RGB buffer and executes the TFLite model immediately:
val inferenceResult = yoloEngine.runInferenceCopy(rgbBuffer)
performance.recordInfer(inferenceResult.infNs)At this point, we have raw YOLO outputs and timing information for the inference itself. But raw results alone aren’t useful we need to process them further.
Decoupling with NMS Tasks
Instead of running NMS inline (which would stall our decode + inference pipeline), we fan out the results into a task queue. This keeps inference responsive and ensures that post-processing happens asynchronously.
We do this by copying the RGB once into a pooled buffer, then packaging the outputs into an NmsTask object:
val nmsTask = NmsTask(
frameIndex = frameIndex,
rgbCopy = rgbCopy,
srcW = srcWidth,
srcH = srcHeight,
infNs = inferenceResult.infNs,
outputCopy = inferenceResult.outputCopy
)
nmsQueue.send(nmsTask)This hand-off step is crucial: inference keeps moving, while NMS can run in its own lane.
Processing NMS in a Worker
On the other end of the queue, a dedicated worker coroutine consumes tasks, runs NMS natively, and decides what to do next:
private fun startNmsWorker() {
nmsWorkerJob?.cancel()
nmsWorkerJob = scope.launch(Dispatchers.Default) {
for (task in nmsQueue) {
val tPost0 = System.nanoTime()
val detections = yoloEngine.postprocessCopiedOutput(task.outputCopy) // NMS
val tPost1 = System.nanoTime()
performance.recordPost(tPost1 - tPost0)If no detections are found, we release the buffers and notify the UI layer with progress updates:
if (detections.isEmpty()) {
releaseRgbCopy(task.rgbCopy)
putFrameDetections(task.frameIndex, emptyList())
val progress = if (totalFramesEstimate > 0) {
(task.frameIndex.toFloat() / totalFramesEstimate) * 100f
} else 0f
withContext(Dispatchers.Main) {
channel.invokeMethod("onProcessingProgress", mapOf(
"progress" to progress,
"totalFrames" to totalFramesEstimate,
"detections" to emptyList<List<Float>>(),
"frameIndex" to task.frameIndex
))
}
}Otherwise, we enqueue the top detections for the ReID stage:
else {
enqueueReIdFromNms(
task.frameIndex,
detections,
task.rgbCopy,
task.srcW,
task.srcH,
task.preNs
)
}Why This Matters
This structure is all about throughput. Inference is expensive, so we don’t want it waiting on NMS. By decoupling the two, we ensure:
- Smooth frame-to-frame flow (decode → inference → next frame).
- Efficient buffer reuse with pooling.
- Asynchronous NMS and ReID without blocking inference.
The result is a pipeline that stays responsive even under heavy loads, while still delivering accurate detections downstream.
Generating ReID Crops from Detections
Once NMS has narrowed down the bounding boxes, the next challenge is Re-Identification (ReID) assigning consistent identities to people across frames. At this point, we already have high-confidence detections, but to track individuals over time we need to feed crops of each detected person into a separate ReID model.
A subtle but important detail: there’s no dedicated “crop stage” floating around in the pipeline. Crops are generated inside the ReID worker itself, as part of its processing flow.
Handing Off from NMS to ReID
After NMS completes, we package everything the ReID worker will need into a ReIDTask. This includes the RGB buffer (the same 384×384 float RGB that YOLO used), the post-NMS detection boxes, and frame metadata. Instead of duplicating buffers or delaying, we simply hand it off.
This keeps the main loop free to continue inference while the ReID stage works asynchronously.
Cropping Inside the ReID Worker
The ReID worker is where the heavy lifting happens. For each task it consumes, it calls assignIdentities(...), which takes care of cropping, resizing, and running the ReID model:
private fun startReIdWorker() {
reIdWorkerJob?.cancel()
reIdWorkerJob = scope.launch(Dispatchers.Default) {
for (task in reIdQueue) {
try {
// Cropping + resizing happens inside assignIdentities
val enriched = reIdProcessor.assignIdentities(
task.rgbCopy,
task.detections,
384, 384
)
// release pooled buffers after processing
releaseRgbCopy(task.rgbCopy)
// ... map and emit results ...
} catch (ce: CancellationException) {
break
} catch (e: Exception) {
Log.e(TAG, "ReID worker error: ${e.message}", e)
}
}
}
}Here, assignIdentities crops each bounding box directly from the rgbCopy, resizes it to the ReID model’s input, and pushes it through the TFLite ReID network. The result is a set of detections now tagged with personId, ready to be tracked across frames.
Queueing for Throughput
Before tasks even reach the ReID worker, we filter detections and only forward the top few. This keeps processing bounded and avoids overwhelming the pipeline:
private suspend fun enqueueReIdFromNms(
frameIndex: Int,
detections: List<FloatArray>,
rgbCopy: ByteBuffer,
srcW: Int,
srcH: Int,
yuvNs: Long
) {
if (detections.isEmpty()) {
releaseRgbCopy(rgbCopy)
return
}
val base = detections.sortedByDescending { it[4] }.take(3) // top 3
reIdQueue.send(ReIdTask(frameIndex, base, rgbCopy, srcW, srcH, yuvNs))
}With this, detections seamlessly flow from YOLO → NMS → ReID, and crops are generated right where they’re needed inside the ReID worker without adding extra stages or overhead.
Here’s how I’d wrap it all up into a polished final section for your blog with a natural tutorial flow, the ReID inference + post-processing explained, and a concluding note that nudges readers to check the demo:
From YOLO Boxes to Stable Person IDs (ReID)
At this point in the pipeline, YOLO has given us bounding boxes, NMS has filtered them down to the best candidates and our pipeline has generated some crops for us. Now comes the last step: Re-Identification (ReID), where we assign stable person IDs across frames. This is what turns “just detections” into trackable individuals.
The entire flow remains in-memory: we reuse the same 384×384 RGB buffer from YOLO, pass it through bounded queues, and keep everything moving without unnecessary copies.
NMS Hands Off to ReID
Once NMS is done, we enqueue a ReIdTask containing:
- The RGB copy (float NHWC, 384×384).
- Post-NMS detections.
- Frame metadata for progress reporting.
private suspend fun enqueueReIdFromNms(
frameIndex: Int,
detections: List<FloatArray>,
rgbCopy: ByteBuffer,=
srcW: Int,
srcH: Int,
yuvNs: Long
) {
if (detections.isEmpty()) {
releaseRgbCopy(rgbCopy)
return
}
if (startTimeNs.get() == 0L) startTimeNs.compareAndSet(0L, System.nanoTime())
val base = detections.sortedByDescending { it[4] }.take(3) // top-K
reIdQueue.send(ReIdTask(frameIndex, base, rgbCopy, srcW, srcH, yuvNs))
}This ensures that the detections flow straight into the ReID worker without stalling the inference loop.
ReID Worker: Crop → Embed → Assign IDs
The ReID worker consumes each task, generates crops from the RGB buffer, runs them through the ReID model, and enriches the detections with a personId.
private fun startReIdWorker() {
reIdWorkerJob?.cancel()
reIdWorkerJob = scope.launch(Dispatchers.Default) {
for (task in reIdQueue) {
try {
val enriched = reIdProcessor.assignIdentities(task.rgbCopy, task.detections, 384, 384)
// enriched format: [x1,y1,x2,y2,score,classId,personId]
val mapped = enriched.map { det ->
val personId = det[6].toInt()
mapOf(
"bbox" to listOf(det[0], det[1], det[2], det[3]),
"score" to det[4],
"personId" to personId
)
}
putFrameDetections(task.frameIndex, mapped)
releaseRgbCopy(task.rgbCopy);
// Send progress and results back to Flutter
val detArrays = mapped.map { m ->
val b = m["bbox"] as List<Float>
val s = (m["score"] as Number).toFloat()
val pid = (m["personId"] as Number).toFloat()
listOf(b[0], b[1], b[2], b[3], s, 0f, pid)
}
val progress = if (totalFramesEstimate > 0)
(task.frameIndex.toFloat() / totalFramesEstimate) * 100f else 0f
withContext(Dispatchers.Main) {
channel.invokeMethod("onProcessingProgress", mapOf(
"progress" to progress,
"totalFrames" to totalFramesEstimate,
"detections" to detArrays,
"frameIndex" to task.frameIndex
))
}
} catch (_: CancellationException) { break }
catch (e: Exception) { Log.e(TAG, "ReID worker error: ${e.message}", e) }
}
}
}Inside assignIdentities
The heart of the process lives in assignIdentities(...):
- Crop each detection from the RGB buffer.
- Resize crops to match the ReID model’s input shape.
- Run inference with the TFLite ReID model to get embedding vectors.
- Match embeddings against the identity gallery. If no match passes the threshold, assign a new personId.
The output for each detection is returned as a float array:
[x1, y1, x2, y2, score, classId, personId]This enriches YOLO’s bounding boxes with stable identity tracking, which is critical for applications like multi-person analytics, surveillance, or sports analysis.
Wrapping It All Up
From decoding raw frames, to running YOLO inference, to filtering with NMS, and finally to assigning stable person IDs with ReID we’ve built a pipeline that stays fully in memory, uses pooling for efficiency, and decouples tasks across workers for smooth throughput.
If you’ve followed along this far, the best way to really appreciate it is to see it in action once our application becomes public (Gait by AICU), and watch how detections turn into stable identities in real time.